I decided to make a grammar library in C#, for inflecting nouns, adjectives, pronouns and verbs. I thought I'd finish the project in a week or two, but the Russian language turned out to be so much more complicated than I ever imagined, even though it's my first language.
Traditionally, as you would learn from the textbooks, there are "only 3 declensions". But the thing is, that's the optimal number of declensions for humans to learn. As you dig deeper, and eliminate the "human intuition" factor, you end up with... approx. 4 558 657 distinct declensions. But, unfortunately, even that amount doesn't cover all the words...
Motivation
In RPG games you often see lines like this: "Gather 4x Coffee Bean". It's quite easy to localize, but it kinda subtracts from the immersiveness of the game. No one in real life would ever say "gather four X Coffee Bean", they'd say "gather four Coffee Beans" instead.
And so, I thought it'd be cool to make a text-based RPG, that, when localized to Russian, would yield really nice, fluently constructed sentences with proper grammar. Sadly, having started working on this project, I don't have the time for this game anymore...[xkcd]
Overview of Russian language
Here's a quick overview of Russian grammar, compared to English grammar, as far as nouns are concerned. Even if you're already familiar with Russian, it'll help put things into perspective.
Grammatical number
Just like English, Russian has singular and plural numbers, as well as singulare tantum and plurale tantum (words that have only one grammatical number, such as "emptiness" and "scissors" in English, and "сено" (hay) and "ножницы" (scissors) in Russian).
In English you can pluralize a word simply by appending s or es to it (plane — planes, box — boxes), and sometimes transforming a few last letters (e.g. lily — lilies).
Russian mostly follows a similar scheme, — appending ы, и, а or я to the word's stem. You can somewhat reliably pick the correct ending based on the word's last letter, but even then, there are numerous exceptions to this rule, even in the simplest of words: сон (dream) — с⋅ны (middle о disappears), глаз (eye) — глаза (а instead of the usual ы after з).
Grammatical case
English only uses cases with pronouns: subjective ("I"), objective ("me"), reflexive ("myself"), possessive ("my"/"mine"). It's the same pronoun, just declined differently. All the other words don't use cases at all.
Russian applies cases to almost all words (nouns, adjectives and pronouns), and there are at least 6 of those cases: nominative ("X is"), genitive ("from X"), dative ("to X"), accusative ("see X"), instrumental ("do sth using X") and prepositional ("about X"). There are also at least 3 rare secondary cases: partitive ("of X"), translative ("into X") and locative ("in X").
Most of the time, a case simply gives the word a different ending: рука (hand), руки, руке, руку, рукой, руке. But, just like with grammatical numbers, the word's stem is often altered unpredictably: боец (fighter), бойца, бойцу, бойцом, бойце.
Grammatical gender
All Russian nouns have a gender, that dictates how the word is declined, what endings it has, and what gender the adjectives referring to it have. There are three: masculine, feminine and neuter ("middle", or inanimate) genders. There's also a relatively rare common gender that depends on the gender of the person it refers to, but it's morphologically identical to feminine, so essentially there are just three.
Russian applies genders to all words: nouns, adjectives, pronouns and even verbs! Makes it hard to form a sentence with yourself in it without specifying your gender. 
Also, sometimes the noun's morphological gender is different from its agreed gender. For example, the word "мужчина" (man) is a masculine noun, but uses feminine endings, and the adjectives that refer to it still treat it as masculine and use masculine endings. (e.g. dative case: красивому (masc.) мужчине (fem.))
So many word forms
Here's what a declension table for a typical noun looks like (2 numbers × 6 cases):
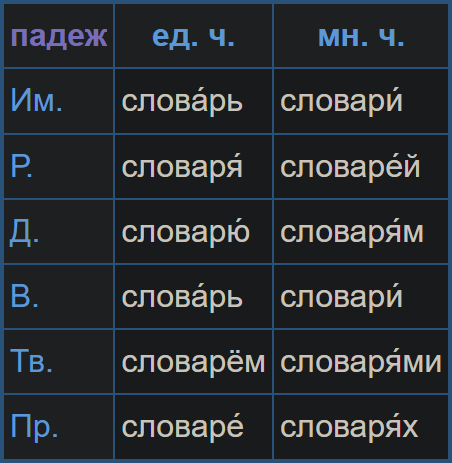
And here's one for a typical adjective (3 genders & plural × 6 cases & short form):
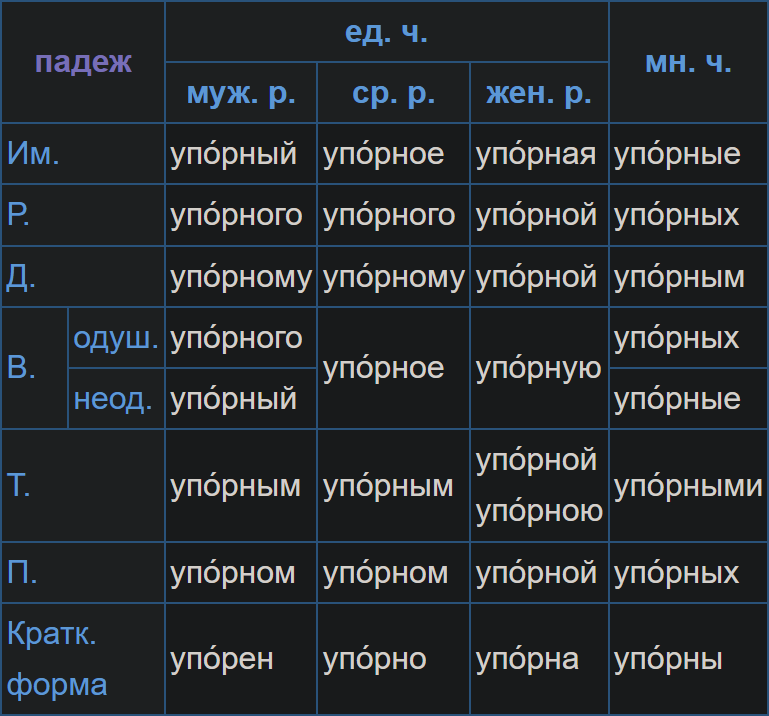
Imagine filling out that many fields, when defining just a single word... Repeating the same exact word in all of its different forms kinda makes you lose sense of what that word even is. "Wait, what does this word mean?", "Am I spelling it right?", "Is that even a real word?" 
And I had to write so many unit tests like this... 
There must be a better way
And yes, luckily, this problem was partially solved by A.A. Zaliznyak in 1977, who created an entire Russian inflection classification system. Each word is assigned a inflection class, consisting of the word's stem type and stress pattern. Some words are also given special flags (*, °, ①, ②, ③) indicating various morphological deviations.
With Zaliznyak's online dictionary in hand, you can define Russian nouns in a single line:
new RussianNoun("кузнец", new("мо 5b"))new RussianNoun("любовь", new("ж 8*b′"))new RussianNoun("глаз", new("м 1c(1)(2)"))new RussianNoun("карько", new("мо <со 3*b(1)(2)>"))
And for defining brand-new words (or simply ones that aren't in the dictionary), I've written a short summary of Zaliznyak's classification here that you can use.
Now, the hardest part is implementing all of this...
Laying the foundation
Enums and noun properties
First things first, the enums: grammatical cases, genders, stress schemas and tantums.
public enum RussianCase {
Nominative, Genitive, Dative, Accusative, Instrumental, Prepositional,
Partitive, Translative, Locative,
}
public enum RussianGender {
Neuter, Masculine, Feminine, Common,
}
public enum RussianStress {
Zero, A, B, C, D, E, F, Ap, Bp, Cp, Dp, Ep, Fp, Cpp, Fpp,
}
public enum RussianTantums {
None, SingulareTantum, PluraleTantum,
}
Then I made a structure representing some of the nouns' properties. I only included gender, animacy and tantums here, since they're the only properties that other parts of speech need to concern themselves with, when declining in agreement with the noun.
public struct RussianNounProperties {
public RussianGender Gender { get; }
public bool IsAnimate { get; }
public RussianTantums Tantums { get; }
}
And then I thought it'd be a good idea to start microoptimizing right away. I put the gender, animacy and tantums in a single byte field.
public struct RussianNounProperties {
// Representation (_data field):
// xxx_xx_x11 - gender (00-11, see RussianGender enum)
// xxx_xx_1xx - animacy (0 - inanimate, 1 - animate)
// xxx_x1_xxx - is plural (0 - singular, 1 - plural; used internally)
// xxx_1x_xxx - tantum indicator (0 - nothing, 1 - "is plural" is the tantum)
// 111_xx_xxx - < UNUSED >
private byte _data;
}
It all fits in just 5 bits, and the extra 3 can be used for something else! For example, the current declension case (the main 6 only), so that you can pass one less parameter to methods.
RussianDeclension structs
After familiarizing myself with the theory of how nouns are declined, I immediately started working on the declension struct:
public struct RussianDeclension {
// Representation (_data field):
// xxxx_1111 - stem type, in range 0-8 (0000-1000)
// 1111_xxxx - stress pattern, in range 0-f″ (0000-1110)
private byte _data;
private byte _flags;
}
But, as I found out a bit later, there were a lot of type-specific rules, properties and value validation, which I won't go into here, but, basically, I had no choice but to split this into several more specific types.
Normally, you'd use abstraction here, and create an interface, which all types of declension would implement. But the problem is, it would be stored on the heap (with an overhead of probably, like, 16 bytes!), and the field would contain a reference to it (8 entire bytes!), and when you call methods on it, the runtime would have to perform virtual table lookups to find the right function to call, which is far from ideal.
And so I came up with this really cool data organization structure:
public struct RussianNounDeclension {
// 00_x_xxxxx - noun declension type constant
// xx_1_xxxxx - noun has special declension properties
// xx_x_11111 - declension gender, animacy and tantums
private byte _typeAndProps;
// xxxx_1111 - stem type
// 1111_xxxx - stress schema
private byte _stemTypeAndStress;
// 1111_1111 - declension flags
private byte _declensionFlags;
}
public struct RussianAdjectiveDeclension {
// 01_xx_xxxx - adjective declension type constant
// xx_x1_xxxx - whether adjective is reflexive
// xx_1x_xxxx - < UNUSED >
// xx_xx_1111 - stem type
private byte _typesAndReflexive;
// xxxx_1111 - main form stress schema
// 1111_xxxx - alternative form stress schema
private byte _stressPattern;
// 1111_1111 - declension flags
private byte _declensionFlags;
}
public struct RussianPronounDeclension {
// 10_xxxxxx - pronoun declension type constant
// xx_111111 - < UNUSED >
private byte _typeAndPadding;
// xxxx_1111 - stem type
// 1111_xxxx - stress schema
private byte _stemTypeAndStress;
// 1111_1111 - declension flags
private byte _declensionFlags;
}
public struct RussianDeclension {
private byte _field1, _field2, _field3;
// Determine the declension type by the first two bits
public RussianDeclensionType Type => (RussianDeclensionType)(_field1 >> 6);
}
All three structures store a type constant (00, 01 or 10) in their first 2 bits. This way, you can cast a RussianNounDeclension to RussianDeclension using Unsafe.As<,>(ref), and then you'll be able to cast it back to the original type. And all of it fits in just 3 bytes! (code link)
NounInfo, AdjectiveInfo structs
Then I needed structures that would aggregate all of the necessary info:
public struct RussianNounInfo {
private RussianNounProperties _props;
private RussianDeclension _declension;
}
public struct RussianAdjectiveInfo {
private RussianDeclension _declension;
private RussianAdjectiveFlags _flags;
}
Now let's see how an entry from Zaliznyak's dictionary translates to this API:
// "девица - жо 5a"
_ = new RussianNounInfo(
new RussianNounProperties(RussianGender.Feminine, isAnimate: true),
new RussianNounDeclension(5, RussianStress.A)
);
And a more complicated example:
// "карько - мо <со 3*b(1)(2)>"
_ = new RussianNounInfo(
// the noun's own properties: masculine gender and animate
new RussianNounProperties(RussianGender.Masculine, isAnimate: true),
// the noun's declension properties:
new RussianNounDeclension(
// stem type 3, stress pattern b
3, RussianStress.B,
// flags *, (1) and (2)
RussianDeclensionFlags.Star | ….CircledOne | ….CircledTwo,
// special declension properties: neuter gender and animate
new RussianNounProperties(RussianGender.Neuter, isAnimate: true)
)
);
Naturally, I implemented parsing and formatting for all those structures as well, so you can just parse any of these structures from a string (or a read-only span of characters):
// Parse noun's gender, animacy, tantums
_ = RussianNounProperties.Parse("мо");
// Parse declension
_ = RussianDeclension.Parse("со 3*b(1)(2)");
// Parse noun's properties and declension
_ = RussianNounInfo.Parse("мо <со 3*b(1)(2)>");
These structures will suffice. Now comes the hard part — the process of declension itself.
Implementing noun declension
Tantums, and common gender
Since I've decided to store tantums, genders and numbers (and even cases sometimes) in RussianNounProperties, all of the preparation can be put in just one method: (code link)
internal void PrepareForDeclensionCase(RussianCase @case, bool plural)
{
// If it doesn't have a tantum, apply specified number
int pluralFlag = IsTantum ? _data & 0b_000_01_000 : plural ? 0b_000_01_000 : 0;
// Convert Common to Feminine gender for endings
int genderFlags = Math.Min(_data & 0b_011, (int)RussianGender.Feminine);
// Preserve animacy, and add case as extra data
_data = (byte)((_data & 0b_100) | pluralFlag | genderFlags | ((int)@case << 5));
}
The resulting structure stores the current declension's gender, number and case, so you only need to pass around two parameters: noun declension and properties. Neat!
Choosing correct endings
Nouns' endings depend on so many factors: case, gender, number, stem type... But I didn't quite fully realize that at first, so I just started switching:
int stemType = declension.StemType;
switch (props.Case)
{
case RussianCase.Nominative:
switch (props.Gender)
{
case RussianGender.Neuter:
if (props.IsPlural)
return stemType switch { 2 => "я", 6 => "ья", 7 => "ия", _ => "а" };
else
return stemType switch { 1 or 3 => "о", 6 => "ье", 7 => "ие", _ => "е" };
case RussianGender.Masculine:
if (props.IsPlural)
return stemType switch { 1 or 5 => "ы", _ => "и" };
else
return stemType switch { 2 => "ь", 6 or 7 => "й", _ => "" };
case RussianGender.Feminine:
if (props.IsPlural)
return stemType switch { 1 or 5 => "ы", _ => "и" };
else
return stemType switch { 2 or 6 or 7 => "я", 8 => "ь", _ => "а" };
}
break;
/* all other cases */
}
The amount of code I had written for just the nominative case was intimidating, but I continued nonetheless, and when writing out the instrumental case case, I noticed that I forgot something important... — stress schemas.
Sometimes the endings of nouns depend on the position of stress in the word. For example, багаж 4b (luggage) and экипаж 4a (crew) have the exact same declensions, minus the stress schemas, but they get different endings in instrumental case: багажóм and экипáжем.
So I had to account for that as well, and wrote a method for determining whether the ending is stressed or not under certain declension parameters: (code link)
[Pure] private static bool IsEndingStressed(NounDecl decl, NounProps props)
{
bool plural = props.IsPlural;
// Accusative case's endings and stresses depend on the noun's animacy.
// Some stresses, though, depend on the original case, like d′ and f′.
RussianCase normCase = props.Case;
if (normCase == RussianCase.Accusative)
normCase = props.IsAnimate ? RussianCase.Genitive : RussianCase.Nominative;
return decl.Stress switch
{
RussianStress.A => false,
RussianStress.B => true,
RussianStress.C => plural,
RussianStress.D => !plural,
RussianStress.E => plural && normCase != RussianCase.Nominative,
RussianStress.F => !plural || normCase != RussianCase.Nominative,
RussianStress.Bp => plural || normCase != RussianCase.Instrumental,
RussianStress.Dp => !plural && props.Case != RussianCase.Accusative,
RussianStress.Fp => plural ? normCase != RussianCase.Nominative : props.Case != RussianCase.Accusative,
RussianStress.Fpp => plural ? normCase != RussianCase.Nominative : normCase != RussianCase.Instrumental,
_ => throw new InvalidOperationException($"{decl.Stress} is not a valid stress pattern for nouns."),
};
}
After adding the necessary stress checks into the code, I realized that it'd probably be better to do some kind of a composite index lookup, rather than doing it all with switch's jump tables. So, I compiled all of the noun declension's endings along with their parameters, and then ran the data through some JS snippets in the browser, and ended up with this:
// All endings of nouns, adjectives and pronouns in one 55-char span
// "оегоговыеейёмойёйамийаямиемуююахяяхыйыхымихомуимиевёвью"
private static ReadOnlySpan<char> EndingSpan =>
[
'о','е','г','о','г','о','в','ы','е','е','й','ё','м','о','й','ё',
'й','а','м','и','й','а','я','м','и','е','м','у','ю','ю','а','х',
'я','я','х','ы','й','ы','х','ы','м','и','х','о','м','у','и','м',
'и','е','в','ё','в','ь','ю',
];
// A compact (576 B) noun ending index lookup
private static ReadOnlySpan<byte> NounLookup =>
[
0x40,0x40,0x41,0x4b,0x40,0x40,0x41,0x40,0x41,0x40,0x41,0x4b,0x41,0x4b,0x40,0x40,
0x01,0x01,0x75,0x75,0x01,0x01,0x01,0x01,0x01,0x01,0x4a,0x4a,0x4a,0x4a,0x75,0x75,
0x51,0x51,0x56,0x56,0x51,0x51,0x51,0x51,0x51,0x51,0x56,0x56,0x56,0x56,0x75,0x75,
0x51,0x51,0x56,0x56,0x51,0x51,0x51,0x51,0x51,0x51,0x56,0x56,0x56,0x56,0x51,0x51,
0x47,0x47,0x53,0x53,0x53,0x53,0x53,0x53,0x47,0x47,0x53,0x53,0x53,0x53,0x53,0x53,
0x47,0x47,0x53,0x53,0x53,0x53,0x53,0x53,0x47,0x47,0x53,0x53,0x53,0x53,0x53,0x53,
0x51,0x51,0x56,0x56,0x51,0x51,0x51,0x51,0x51,0x51,0x56,0x56,0x56,0x56,0x51,0x51,
0x51,0x51,0x56,0x56,0x51,0x51,0x51,0x51,0x51,0x51,0x56,0x56,0x56,0x56,0x53,0x53,
0x47,0x47,0x53,0x53,0x53,0x53,0x53,0x53,0x47,0x47,0x53,0x53,0x53,0x53,0x53,0x53,
0x01,0x01,0x75,0x89,0x01,0x01,0x01,0x89,0x01,0x01,0x4a,0x4a,0x4a,0x4a,0x01,0x01,
0x85,0x85,0x89,0x89,0x85,0x85,0x89,0x89,0xb1,0x85,0xb1,0xb3,0xb1,0xb3,0x89,0x89,
0x01,0x01,0x75,0x89,0x01,0x01,0x01,0x89,0x01,0x01,0x4a,0x4a,0x4a,0x4a,0x89,0x89,
0x5b,0x5b,0x5c,0x5c,0x5b,0x5b,0x5b,0x5b,0x5b,0x5b,0x5c,0x5c,0x5c,0x5c,0x5b,0x5b,
0x5b,0x5b,0x5c,0x5c,0x5b,0x5b,0x5b,0x5b,0x5b,0x5b,0x5c,0x5c,0x5c,0x5c,0x53,0x53,
0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x53,0x41,0x53,0x53,
0x91,0x91,0x96,0x96,0x91,0x91,0x91,0x91,0x91,0x91,0x96,0x96,0x96,0x96,0x91,0x91,
0x91,0x91,0x96,0x96,0x91,0x91,0x91,0x91,0x91,0x91,0x96,0x96,0x96,0x96,0x96,0x96,
0x91,0x91,0x96,0x96,0x91,0x91,0x91,0x91,0x91,0x91,0x96,0x96,0x96,0x96,0x96,0x96,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0x5b,0x5b,0x5c,0x5c,0x5b,0x5b,0x5b,0x5b,0x5b,0x5b,0x5c,0x5c,0x5c,0x5c,0x75,0x75,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0xab,0xab,0x99,0x8b,0xab,0xab,0x99,0xab,0x99,0xab,0x99,0x8b,0x99,0x8b,0xab,0xab,
0xab,0xab,0x99,0x8b,0xab,0xab,0x99,0xab,0x99,0xab,0x99,0x8b,0x99,0x8b,0x99,0x8b,
0x8d,0x8d,0x89,0x8f,0x8d,0x8d,0x89,0x8d,0x89,0x8d,0x89,0x8f,0x89,0x8f,0xb5,0xb5,
0xd1,0xd1,0xd6,0xd6,0xd1,0xd1,0xd1,0xd1,0xd1,0xd1,0xd6,0xd6,0xd6,0xd6,0xd1,0xd1,
0xd1,0xd1,0xd6,0xd6,0xd1,0xd1,0xd1,0xd1,0xd1,0xd1,0xd6,0xd6,0xd6,0xd6,0xd6,0xd6,
0xd1,0xd1,0xd6,0xd6,0xd1,0xd1,0xd1,0xd1,0xd1,0xd1,0xd6,0xd6,0xd6,0xd6,0xd6,0xd6,
0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x53,0x41,0x53,0x53,
0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x53,0x41,0x53,0x53,
0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x41,0x53,0x41,0x53,0x53,
0x9e,0x9e,0xa1,0xa1,0x9e,0x9e,0x9e,0x9e,0x9e,0x9e,0xa1,0xa1,0xa1,0xa1,0x9e,0x9e,
0x9e,0x9e,0xa1,0xa1,0x9e,0x9e,0x9e,0x9e,0x9e,0x9e,0xa1,0xa1,0xa1,0xa1,0xa1,0xa1,
0x9e,0x9e,0xa1,0xa1,0x9e,0x9e,0x9e,0x9e,0x9e,0x9e,0xa1,0xa1,0xa1,0xa1,0xa1,0xa1,
];
Essentially, I put all of the ending selection logic in an array, instead of writing it out explicitly in an enormous many kilobytes-long method body. It's kinda like a multi-dimensional jump-table, but without any gaps, if that makes sense. (code link)
The "composite index" is calculated from all of the declension parameters:
[Pure] private static int ComposeNounEndingIndex(NounDecl decl, NounProps props, RussianCase @case)
{
// Composite index: [case:6] [plural:2] [gender:3] [stem type:8] [stress:2]
int index = (int)@case;
index = index * 2 + (props.IsPlural ? 1 : 0);
index = index * 3 + (int)props.Gender;
index = index * 8 + (decl.StemType - 1);
index *= 2; // stress takes up the least significant bit
return index;
}
Then this composite index is used to index that huge NounLookup array, and the byte you get represents an ending in EndingSpan: start index (6 bits) and length (2 bits).
[Pure] public static (byte, byte) GetNounEndingIndices(NounDecl decl, NounProps props)
{
ReadOnlySpan<byte> lookup = NounLookup;
// Get indices of both unstressed and stressed forms of endings (usually they're the same)
int lookupIndex = ComposeNounEndingIndex(decl, props, props.Case);
byte unStrIndex = lookup[lookupIndex];
// Accusative case usually uses either genitive's or nominative's ending, depending on animacy.
// In such case, the lookup yields index 0. Don't confuse with "" (encoded as 0x01: pos=1, length=0).
if (unStrIndex == 0)
{
lookupIndex = ComposeNounEndingIndex(decl, props, props.IsAnimate ? RussianCase.Genitive : RussianCase.Nominative);
unStrIndex = lookup[lookupIndex];
}
// Stressed ending index is right next to the unstressed one's
byte strIndex = lookup[lookupIndex + 1];
return (unStrIndex, strIndex);
}
If the resulting stressed and unstressed indices are different, then IsEndingStressed(…) is called, to determine which one should be used.
[Pure] private static ReadOnlySpan<char> DetermineEnding(NounDecl decl, NounProps props)
{
var (unStressedIndex, stressedIndex) = RussianEndings.GetNounEndingIndices(decl, props);
bool stressed = unStressedIndex != stressedIndex && IsEndingStressed(decl, props);
return RussianEndings.Get(stressed ? stressedIndex : unStressedIndex);
}
And finally, the EndingSpan is sliced, and the appropriate ending is returned.
[Pure] public static ReadOnlySpan<char> Get(byte endingIndex)
=> EndingSpan.Slice(endingIndex & 0x3F, endingIndex >> 6);
It's very complicated (maybe overcomplicated), but it works pretty well! I will do some benchmarks later, to actually make sure that it's not slower than just one giant switch.
Endings of a different gender
Very rarely, nouns use endings characteristic of a different gender, and in Zaliznyak's classification that's indicated by specifying the "morphological gender" in angled brackets along with the noun's inflection class, after the noun's actual gender:
- мужчина мо <жо 1a> (man):
singular: мужчин⋅, мужчине, мужчину, мужчиной, мужчине.
plural: мужчины, мужчин⋅, мужчинами, мужчинах. - старейшина мо <жо 1a> (elder):
singular: старейшины, старейшине, старейшину, старейшиной, старейшине.
plural: старейшины, старейшин⋅, старейшинам, старейшинами, старейшинах.
This is implemented simply by storing two sets of noun properties: one for declension (stored in RussianNounDeclension), and another one for everything else (stored in RussianNounInfo).
There are also nouns that use different endings in only one or two forms, and the gender alternation is straightforward: masculine → neuter, neuter/feminine → masculine. This can apply only to the plural forms of nominative (indicated by ①) and genitive (indicated by ②) cases.
- поезд м 1c① (train): nom. поезда (neut./fem. instead of masc. ы), gen. поездов.
- облако с 3c② (cloud): nom. облака, gen. облаков (masc. instead of neut./fem. ⋅).
- глаз м 1c①② (eye): nom. глаза (instead of usual ы), gen. глаз⋅ (instead of usual ов).
In addition to ① and ②, there's a similar flag ③, that's only used for a few stem type 7 words, indicating that in modern literature the noun's singular prepositional form more often has the ending е, instead of the typical и: чий — о чие, Лия — о Лие.
Since these three flags only affect the choice of an ending and nothing else, I implemented them as part of RussianNoun.DetermineEnding(,) method. (code link)
There are also nouns that mix the two above-described ending-altering methods, that essentially allow the word to revert back to its actual gender in some cases:
- глазище м <с 4a①> (eye, augmentative form):
singular: глазища, глазищу, глазищем, глазище.
plural: глазищи (instead of а), глазищ⋅, глазищам, глазищами, глазищах. - Серко мо <со 3*b①②> (Serko, a horse name):
singular: Серка, Серку, Серком, Серке.
plural: Серки (instead of а), Серков (instead of ⋅), Серкам, Серками, Серках.
Vowel alternation in the stem
One of the most common morphological deviations, one you've already seen in this post, is the alternation of vowels in the stem (indicated by * in Zaliznyak's classification):
- сон м 1*b (dream) — с⋅на, с⋅ну, с⋅ном, с⋅не.
The vowel о disappears in all forms, except nominative. - лёд м 1*b (ice) — льда, льду, льдом, льде.
The vowel ё turns into ь in all forms, except nominative, if it's after an л (or if the stem type is 6, or if stem type is 3 and the vowel is after a sibilant ж/ц/ч/ш/щ). - кук⋅ла ж 1*a (doll) — plural: кук⋅лы, кукол⋅, кук⋅лам, кук⋅лами, кук⋅лах.
The vowel о appears between the last two letters in genitive plural, if it's after к/г/х and not followed by a sibilant ж/ц/ч/ш/щ. - баш⋅ня ж 2*a (tower) — plural: баш⋅ни, башен⋅, баш⋅ням, баш⋅нями, баш⋅нях.
The vowel е appears between the last two letters in genitive plural, in all other cases that aren't covered by other rules (not mentioned here), but only if the ending isn't stressed. Also, the usual ending of ь is removed if the noun is feminine and ends with н.
The vowel alternation rules are very complicated, and these examples only represent a small portion of them (you'd need over 80 example words to fully describe all the rules). If you'd like to know more, check the 100+ lines of code here.
е/ё alternation in the stem
Separate from vowel alternation, there's a е/ё alternation (indicated by ", ё"). Some words have both a vowel alternation, and a е/ё alternation, such as стек⋅лó (glass) or сест⋅рá (sister). This alternation heavily depends on words' stress patterns, since ё in Russian can only be stressed.
- шёлк м 3c①, ё (silk):
singular: шёлка, шёлку, шёлком, шёлке.
plural: шелкá, шелкóв, шелкáм, шелкáми, шелкáх. - жёлудь м 2e, ё (acorn):
singular: жёлудя, жёлудю, жёлудем, жёлуде.
plural: жёлуди, желудéй, желудя́м, желудя́ми, желудя́х. - стек⋅лó с 1*d, ё (glass):
singular: стек⋅лá, стек⋅лý, стек⋅лóм, стек⋅лé.
plural: стёк⋅ла, стёкол⋅, стёк⋅лам, стёк⋅лами, стёк⋅лах. - сест⋅ра жо 1*d, ё (sister):
singular: сест⋅ры́, сест⋅рé, сест⋅рý, сест⋅рóй, сест⋅рé.
plural: сёст⋅ры, сестёр⋅ (anomalous stress shift), сёст⋅рам, сёст⋅рами, сёст⋅рах.
е/ё alternation rules are much simpler, and fit in just ~30 lines of code.
Unique stem alternations
Another, more unusual, alternation is the unique stem alternation (indicated by °). It applies to a handful of special morphological shapes: -ин, -ёнок, -онок, -ёночек, -оночек, -ок, -мя.
- крестьянин мо 1°a (peasant):
singular: крестьянине, крестьянину, крестьянином, крестьянине.
plural: крестьян⋅е, крестьян⋅⋅, крестьян⋅ам, крестьян⋅ами, крестьян⋅ах. - утёнок мо 3°a (duckling) — singular: утёнка, утёнку, утёнком, утёнке.
plural: утята, утят⋅, утятам, утятами, утятах. - поросёночек мо 3°a (piglet, diminutive form):
singular: поросёночка, поросёночку, поросёночком, поросёночке.
plural: поросятки, поросяток⋅, поросяткам, поросятками, поросятках. - щенок мо 3°d (puppy) — singular: щенка, щенку, щенком, щенке.
plural: щенята, щенят⋅, щенятам, щенятами, щенятах. - время с 8°c, ё (time) — singular: времени, временем.
plural: времена, времён⋅, временам, временами, временах.
Once again, the rules are complicated, so see the code if you want to know more.
Putting it all together
Now we combine everything we've implemented so far, and... ta-da!  (code link)
(code link)
[Pure] internal static string DeclineCore(ReadOnlySpan<char> stem, NounDecl decl, NounProps props)
{
if (decl.IsZero) return stem.ToString();
// Allocate some memory for string manipulations
const int extraCharCount = 8;
Span<char> buffer = stackalloc char[stem.Length + extraCharCount];
InflectionBuffer results = new(buffer);
// Find the appropriate noun ending
ReadOnlySpan<char> ending = DetermineEnding(decl, props);
// Write the stem and ending into the buffer
results.WriteInitialParts(stem, ending);
// If declension has a circle, apply the systematic alternation
if ((decl.Flags & RussianDeclensionFlags.Circle) != 0)
ProcessUniqueAlternation(ref results, decl, props);
// Replace 'я' in endings with 'а', if it's after a hissing consonant
if (decl.StemType == 8 && ending.Length > 0 && ending[0] == 'я' && RussianLowerCase.IsHissingConsonant(stem[^1]))
results.Ending[0] = 'а';
// If declension has a star, figure out the vowel and where to place it
if ((decl.Flags & RussianDeclensionFlags.Star) != 0)
ProcessVowelAlternation(ref results, decl, props);
if ((decl.Flags & RussianDeclensionFlags.AlternatingYo) != 0)
ProcessYoAlternation(ref results, decl, props);
return results.Result.ToString();
}
With this, we can correctly decline pretty much all nouns*†§ in the Russian language!
using GrammarSharp.Russian;
var noun = new RussianNoun("зверёк", new("мо 3*b"));
_ = noun.Decline(RussianCase.Dative, plural: false); // "зверьку"
_ = noun.Decline(RussianCase.Dative, plural: true); // "зверькам"
* except nouns that decline like adjectives (have an adjective declension).
† and except nouns that have special secondary case forms (locative, partitive, translative).
§ and except the hundreds of anomalous nouns, the unruly morphology and inflection of which are beyond any mortal grammarian's attempts at classification...
... Well, fine. But at least it covers, 97.6% of all use cases!
I'll cover the remaining 2.4% in the next post, "GrammarSharp (Part 2): […]".
Conclusion
Most other Russian grammar solutions require a built-in dictionary, that may weigh up to several megabytes, while the library I implemented doesn't require such a dictionary! You just need to include the declension classes of the words you need, to properly decline them.
While there's still a lot left to implement, if you're in need of advanced Russian grammar, you can go ahead and start using the pre-release versions of the package on NuGet: https://www.nuget.org/packages/GrammarSharp.Russian.
I've already implemented adjective and pronoun declensions, and even started on numerals (which are turning out to be almost just as complicated as nouns were initially). I'll cover those in the future posts, so subscribe to my blog's RSS feed to stay tuned! 