I checked the source code of some SemVer C# libraries, and found out that all of them allocate memory excessively, use LINQ and even Regexes, and that's practically a crime!
And so, as someone who only at one single point in their life ever needed a SemVer library, I decided to develop my own solution, — Chasm.SemanticVersioning, that doesn't allocate that much unnecessary memory!
Motivation and goals
I wanted the default comparison to ignore build metadata identifiers, as specified by SemVer. While build-metadata-sensitive comparison makes sense from a structural standpoint, it doesn't from a behavioral one, and I wanted 1.0.0+9B4AF2 to be considered equal to 1.0.0 by default.
I also didn't like how a SemanticVersion can be constructed from a string in other libraries. The constructor should not be responsible for parsing a string, that's just weird, and also encourages people to write worse code: new("1.0.0-pre") (which involves parsing) instead of new(1, 0, 0, ["pre"]) (simple object creation).
Most libraries often only offer the basic string parsing and formatting, and I wanted ISpanParsable and ISpanFormattable support, for efficiency and stuff. I also wanted to annotate stuff with attributes for proper nullable analysis.
Other libraries always convert stuff like ^5 to >=5.0.0 <6.0.0-0. So you can't even really edit anything, the parsers just destroy all the nice, sugared, user-friendly syntax. I wanted my library to preserve all of this advanced comparator syntax.
Also, sometimes you'd need to slightly change user-specified versions, but you don't wanna break their sugared comparators (^1.0.0). I decided that I would implement range operators. Like, "^1.0.0" & ">=1.2.3" = "^1.2.3". It was incredibly complicated, but I managed to do it!
Working on the project
This project took a lot of time and work, but I wasn't keeping a log or anything, so... Idk. It just kind of worked out, and I've implemented everything I wanted, and learned a lot of stuff.
Just take a look at the repository's commit history, and that should tell you everything. I often got distracted by other stuff, went on a lot of tangents, and the repository became an amalgam of several different projects...
I'll just describe the parsing and formatting part of it here, and show the results at the end.
Chasm.Formatting package
The project went through many iterations before getting to its current state. Parsing and formatting were the most troublesome, as I wanted them to be more-or-less easy to read in the source code, but still as performant as possible.
I really liked the API I wound up with, and decided to put these in a separate library, for use in other projects (like GrammarSharp, which I'll make a post about soon). Here's a quick overview:
SpanParser structure
SpanParser is used to read a span of characters sequentially. It's meant to significantly reduce the amount of boilerplate code, that's common in many high-performance parsers:
ReadOnlySpan<char> text = "$var = [value];";
int position = 0;
if (position < text.Length && text[position] is '$' or '@')
{
position++;
int varNameStart = position;
while (position < text.Length && char.IsAsciiLetter(text[position])) position++;
ReadOnlySpan<char> varName = text[varNameStart..position];
while (position < text.Length && char.IsWhitespace(text[position])) position++;
}
The above can be rewritten using a SpanParser like this:
SpanParser parser = new("$var = [value];");
if (parser.SkipAny('$', '@'))
{
ReadOnlySpan<char> varName = parser.ReadAsciiLetters();
parser.SkipWhitespaces();
}
All the method calls are inlined, so they don't degrade the performance much. It's a little bit slower than typical code, but much easier to understand, and also error-proof!
SpanBuilder structure
SpanBuilder allocates a string of the exact required length and formats directly into it, removing the need for renting buffers, using dynamically-resized StringBuilders, and even copying!
public sealed class SemanticVersion : ISpanBuildable
{
public void CalculateLength()
{
int length = 2
+ SpanBuilder.CalculateLength((uint)Major)
+ SpanBuilder.CalculateLength((uint)Minor)
+ SpanBuilder.CalculateLength((uint)Patch);
/* add pre-releases and build metadata length */
return length;
}
public void BuildString(ref SpanBuilder sb)
{
sb.Append((uint)Major);
sb.Append('.');
sb.Append((uint)Minor);
sb.Append('.');
sb.Append((uint)Patch);
/* append pre-releases and build metadata identifiers */
}
}
The length of your formatted object needs to be relatively easy to calculate though, like, just regular integers and strings, without much complex manipulations with either.
Tests and code coverage
I've probably spent weeks just writing the tests...
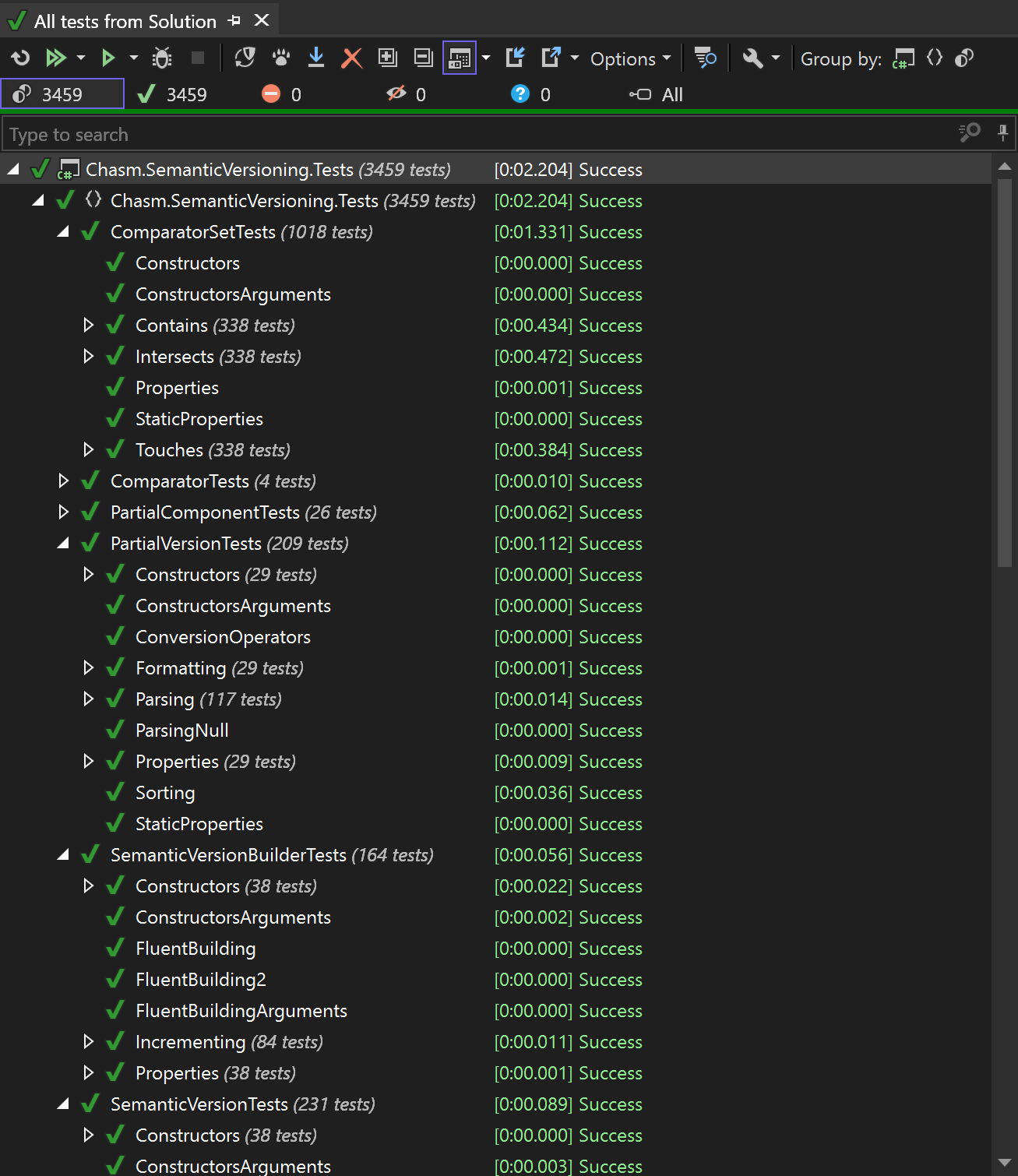
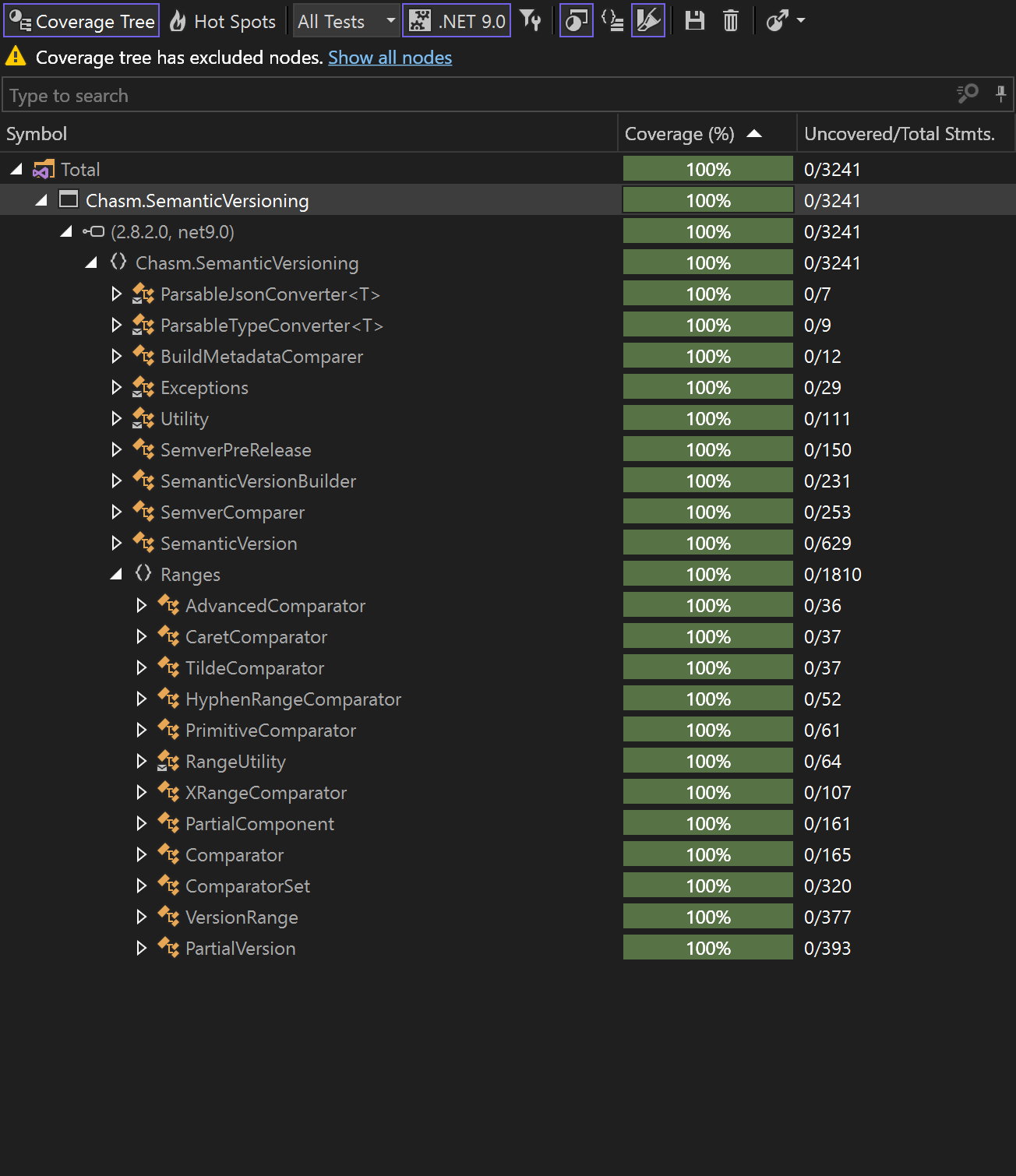
It doesn't take much knowledge to write them, but it does take a lot of perseverance.
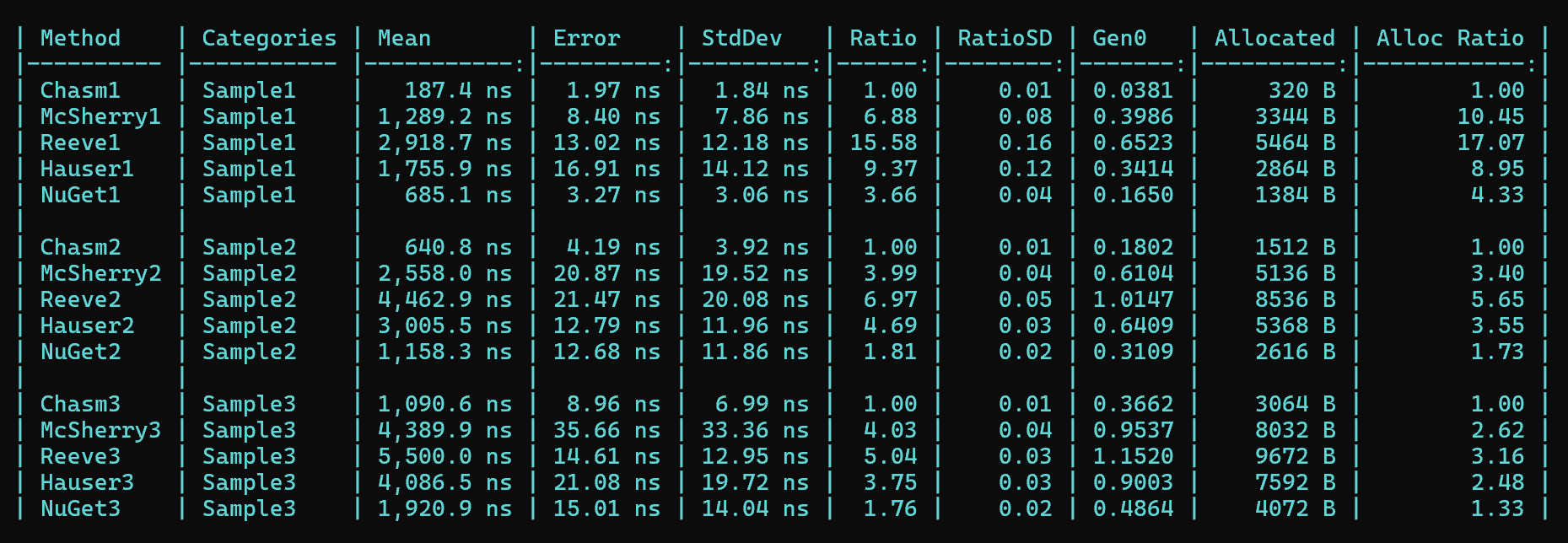
Benchmarks
My library, Chasm.SemanticVersioning, significantly outperforms all other benchmarked libraries, in both mean execution time and amount of allocated memory.
You can find all of the benchmarks here.
I wonder how a SemVer library written in Rust would compare to these...
Some other helper libraries
I've also made a few helper libraries, that I developed alongside Chasm.SemanticVersioning. I probably should have split them into separate repositories, but I realized that too late.
Chasm.Collections- various extensions for collections.Chasm.Utilities- utilities to reduce boilerplate code.Chasm.Compatibility- support for newer API for a wide range of targets.
Conclusion
Well, that's it for this post. It turned out very disorganized, but, I guess, I just don't have much to share about the development process.
I'll be making another post soon, about GrammarSharp, a grammar/inflection library I've been working on, that supports inflecting Russian nouns, adjectives and pronouns. I thought I'd finish the project in a week or two, but the Russian language turned out to be so much more complicated than I ever imagined, even though it's my first language...